Docker部署Mysql集群的实现
单节点数据库的弊病
- 大型互联网程序用户群体庞大,所以架构必须要特殊设计
- 单节点的数据库无法满足性能上的要求
- 单节点的数据库没有冗余设计,无法满足高可用
单节点MySQL的性能瓶领颈
2016年春节微信红包巨大业务量,数据库承受巨大负载

常见MySQL集群方案
mysql 集群方案介绍,建议使用pxc,因为弱一致性会有问题,比如说a节点数据库显示我购买成功,b 节点数据库显示没有成功,这就麻烦了,pxc 方案是在全部节点都写入成功之后才会告诉你成功,是可读可写双向同步的,但是replication是单向的,不同节点的数据库之间都会开放端口进行通讯,如果从防火墙的这个端口关闭,pxc就不会同步成功,也不会返给你成功了。

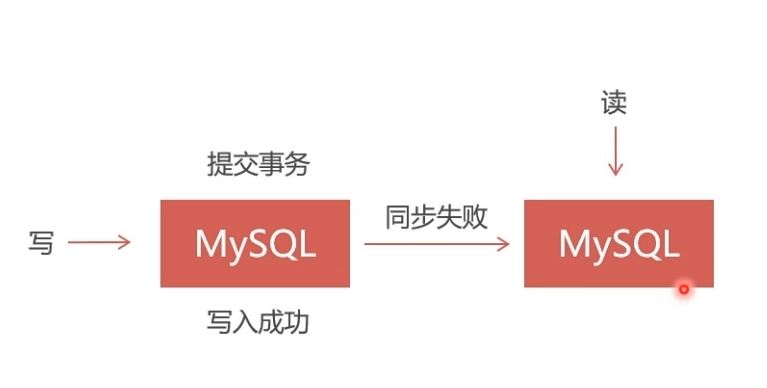
Replication
- 速度快,但仅能保证弱一致性,适用于保存价值不高的数据,比如日志、帖子、新闻等。
- 采用master-slave结构,在master写入会同步到slave,能从slave读出;但在slave写入无法同步到master。
- 采用异步复制,master写入成功就向客户端返回成功,但是同步slave可能失败,会造成无法从slave读出的结果。

PXC (Percona XtraDB Cluster)
- 速度慢,但能保证强一致性,适用于保存价值较高的数据,比如订单、客户、支付等。
- 数据同步是双向的,在任一节点写入数据,都会同步到其他所有节点,在任何节点上都能同时读写。
- 采用同步复制,向任一节点写入数据,只有所有节点都同步成功后,才会向客户端返回成功。事务在所有节点要么同时提交,要么不提交。

建议PXC使用PerconaServer (MySQL改进版,性能提升很大)
PXC的数据强一致性
同步复制,事务在所有集群节点要么同时提交,要么不提交 Replication采用异步复制,无法保证数据的一致性

PXC集群安装介绍
在Docker中安装PXC集群,使用Docker仓库中的PXC官方镜像:https://hub.docker.com/r/percona/percona-xtradb-cluster
1、从docker官方仓库中拉下PXC镜像:
docker pull percona/percona-xtradb-cluster
或者本地安装
docker load < /home/soft/pxc.tar.gz
安装完成:
[root@localhost ~]# docker pull percona/percona-xtradb-cluster Using default tag: latest Trying to pull repository docker.io/percona/percona-xtradb-cluster ... latest: Pulling from docker.io/percona/percona-xtradb-cluster ff144d3c0ab1: Pull complete eafdff1524b5: Pull complete c281665399a2: Pull complete c27d896755b2: Pull complete c43c51f1cccf: Pull complete 6eb96f41c54d: Pull complete 4966940ec632: Pull complete 2bafadcea292: Pull complete 3c2c0e21b695: Pull complete 52a8c2e9228e: Pull complete f3f28eb1ce04: Pull complete d301ece75f56: Pull complete 3d24904bec3c: Pull complete 1053c2982c37: Pull complete Digest: sha256:17c64dacbb9b62bd0904b4ff80dd5973b2d2d931ede2474170cbd642601383bd Status: Downloaded newer image for docker.io/percona/percona-xtradb-cluster:latest [root@localhost ~]# docker images REPOSITORY TAG IMAGE ID CREATED SIZE docker.io/percona/percona-xtradb-cluster latest 70b3670450ef 2 months ago 408 MB
2、重命名镜像:(名称太长,重命名一下)
docker tag percona/percona-xtradb-cluster:latest pxc
然后原来的镜像就可以删除掉了
[root@localhost ~]# docker images REPOSITORY TAG IMAGE ID CREATED SIZE docker.io/percona/percona-xtradb-cluster latest 70b3670450ef 2 months ago 408 MB pxc latest 70b3670450ef 2 months ago 408 MB docker.io/java latest d23bdf5b1b1b 2 years ago 643 MB [root@localhost ~]# docker rmi docker.io/percona/percona-xtradb-cluster Untagged: docker.io/percona/percona-xtradb-cluster:latest Untagged: docker.io/percona/percona-xtradb-cluster@sha256:17c64dacbb9b62bd0904b4ff80dd5973b2d2d931ede2474170cbd642601383bd [root@localhost ~]# docker images REPOSITORY TAG IMAGE ID CREATED SIZE pxc latest 70b3670450ef 2 months ago 408 MB docker.io/java latest d23bdf5b1b1b 2 years ago 643 MB
3、出于安全考虑,给PXC集群创建Docker内部网络
# 创建网段 docker network create --subnet=172.18.0.0/24 net1 # 查看网段 docker network inspect net1 # 删除网段 # docker network rm net1
4、创建Docker卷:
使用Docker时,业务数据应保存在宿主机中,采用目录映射,这样可以使数据与容器独立。但是容器中的PXC无法直接使用映射目录,解决办法是采用Docker卷来映射
# 创建名称为v1的数据卷,--name可以省略 docker volume create --name v1
查看数据卷
docker inspect v1
结果:
[root@localhost ~]# docker inspect v1
[
{
"Driver": "local",
"Labels": {},
"Mountpoint": "/var/lib/docker/volumes/v1/_data",#这里是在宿主机的保存位置
"Name": "v1",
"Options": {},
"Scope": "local"
}
]
删除数据卷
docker volume rm v1
创建5个数据卷
# 创建5个数据卷 docker volume create --name v1 docker volume create --name v2 docker volume create --name v3 docker volume create --name v4 docker volume create --name v5
5、创建5个PXC容器:
# 创建5个PXC容器构成集群 # 第一个节点 docker run -d -p 3306:3306 -e MYSQL_ROOT_PASSWORD=abc123456 -e CLUSTER_NAME=PXC -e XTRABACKUP_PASSWORD=abc123456 -v v1:/var/lib/mysql --name=node1 --network=net1 --ip 172.18.0.2 pxc # 在第一个节点启动后要等待一段时间,等候mysql启动完成。 # 第二个节点 docker run -d -p 3307:3306 -e MYSQL_ROOT_PASSWORD=abc123456 -e CLUSTER_NAME=PXC -e XTRABACKUP_PASSWORD=abc123456 -e CLUSTER_JOIN=node1 -v v2:/var/lib/mysql --name=node2 --net=net1 --ip 172.18.0.3 pxc # 第三个节点 docker run -d -p 3308:3306 -e MYSQL_ROOT_PASSWORD=abc123456 -e CLUSTER_NAME=PXC -e XTRABACKUP_PASSWORD=abc123456 -e CLUSTER_JOIN=node1 -v v3:/var/lib/mysql --name=node3 --net=net1 --ip 172.18.0.4 pxc # 第四个节点 docker run -d -p 3309:3306 -e MYSQL_ROOT_PASSWORD=abc123456 -e CLUSTER_NAME=PXC -e XTRABACKUP_PASSWORD=abc123456 -e CLUSTER_JOIN=node1 -v v4:/var/lib/mysql --name=node4 --net=net1 --ip 172.18.0.5 pxc # 第五个节点 docker run -d -p 3310:3306 -e MYSQL_ROOT_PASSWORD=abc123456 -e CLUSTER_NAME=PXC -e XTRABACKUP_PASSWORD=abc123456 -e CLUSTER_JOIN=node1 -v v5:/var/lib/mysql --name=node5 --net=net1 --ip 172.18.0.6 pxc
查看:
[root@localhost ~]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES f4708ce32209 pxc "/entrypoint.sh " About a minute ago Up About a minute 4567-4568/tcp, 0.0.0.0:3309->3306/tcp node4 bf612f9586bc pxc "/entrypoint.sh " 17 minutes ago Up 17 minutes 4567-4568/tcp, 0.0.0.0:3310->3306/tcp node5 9fdde5e6becd pxc "/entrypoint.sh " 17 minutes ago Up 17 minutes 4567-4568/tcp, 0.0.0.0:3308->3306/tcp node3 edd5794175b6 pxc "/entrypoint.sh " 18 minutes ago Up 18 minutes 4567-4568/tcp, 0.0.0.0:3307->3306/tcp node2 33d842de7f42 pxc "/entrypoint.sh " 21 minutes ago Up 21 minutes 0.0.0.0:3306->3306/tcp, 4567-4568/tcp node1
数据库负载均衡的必要性
虽然搭建了集群,但是不使用数据库负载均衡,单节点处理所有请求,负载高,性能差

将请求均匀地发送给集群中的每一个节点。
- 所有请求发送给单一节点,其负载过高,性能很低,而其他节点却很空闲。
- 使用Haproxy做负载均衡,可以将请求均匀地发送给每个节点,单节点负载低,性能好

负载均衡中间件对比
负载均衡首先是数据库的集群,加入5个集群,每次请求都是第一个的话,有可能第一个数据库就挂掉了,所以更优的方案是对不同的节点都进行请求,这就需要有中间件进行转发,比较好的中间件有nginx,haproxy等,因nginx 支持插件,但是刚刚支持了tcp/ip 协议,haproxy 是一个老牌的中间转发件。如果要用haproxy的话,可以从官方下载镜像,然后呢对镜像进行配置(自己写好配置文件,因为这个镜像是没有配置文件的,配置好之后再运行镜像的时候进行文件夹的映射,配置文件开放3306(数据库请求,然后根据check心跳检测访问不同的数据库,8888 对数据库集群进行监控))。配置文件里面设置用户(用户在数据库进行心跳检测,判断哪个数据库节点是空闲的,然后对空闲的进行访问),还有各种算法(比如轮训),最大连接数,时间等,还有对集群的监控。配置文件写好以后运行这个镜像,镜像运行成功后进入容器启动配置文件 。其实haprocy返回的也是一个数据库实例(但是并不存储任何的数据,只是转发请求),这个实例用来check其他节点。

安装Haproxy
1、从Docker仓库拉取haproxy镜像:https://hub.docker.com/_/haproxy
docker pull haproxy
[root@localhost ~]# docker images REPOSITORY TAG IMAGE ID CREATED SIZE docker.io/haproxy latest 11fa4d7ff427 11 days ago 72.2 MB
2、创建Haproxy配置文件。供Haproxy容器使用(docker中未生成配置文件,我们需要在宿主机中自己创建配置文件)
配置文件详情参考:https://www.cnblogs.com/wyt007/p/10829184.html
# 启动容器时使用目录映射技术使容器读取该配置文件 touch /home/soft/haproxy/haproxy.cfg
haproxy.cfg
# haproxy.cfg global #工作目录 chroot /usr/local/etc/haproxy #日志文件,使用rsyslog服务中local5日志设备(/var/log/local5),等级info log 127.0.0.1 local5 info #守护进程运行 daemon defaults log global mode http #日志格式 option httplog #日志中不记录负载均衡的心跳检测记录 option dontlognull #连接超时(毫秒) timeout connect 5000 #客户端超时(毫秒) timeout client 50000 #服务器超时(毫秒) timeout server 50000 #监控界面 listen admin_stats #监控界面的访问的IP和端口 bind 0.0.0.0:8888 #访问协议 mode http #URI相对地址 stats uri /dbs #统计报告格式 stats realm Global\ statistics #登陆帐户信息 stats auth admin:abc123456 #数据库负载均衡 listen proxy-mysql #访问的IP和端口 bind 0.0.0.0:3306 #网络协议 mode tcp #负载均衡算法(轮询算法) #轮询算法:roundrobin #权重算法:static-rr #最少连接算法:leastconn #请求源IP算法:source balance roundrobin #日志格式 option tcplog #在MySQL中创建一个没有权限的haproxy用户,密码为空。Haproxy使用这个账户对MySQL数据库心跳检测 option mysql-check user haproxy server MySQL_1 172.18.0.2:3306 check weight 1 maxconn 2000 server MySQL_2 172.18.0.3:3306 check weight 1 maxconn 2000 server MySQL_3 172.18.0.4:3306 check weight 1 maxconn 2000 server MySQL_4 172.18.0.5:3306 check weight 1 maxconn 2000 server MySQL_5 172.18.0.6:3306 check weight 1 maxconn 2000 #使用keepalive检测死链 option tcpka
3、在数据库集群中创建空密码、无权限用户haproxy,来供Haproxy对MySQL数据库进行心跳检测
create user 'haproxy'@'%' identified by '';
4、创建Haproxy容器(name=h1的原因是为了高可用)
# 这里要加 --privileged docker run -it -d -p 4001:8888 -p 4002:3306 -v /home/soft/haproxy:/usr/local/etc/haproxy --name h1 --net=net1 --ip 172.18.0.7 --privileged haproxy
5、进入容器
docker exec -it h1 bash
6、在容器bash中启动Haproxy
haproxy -f /usr/local/etc/haproxy/haproxy.cfg
接下来便可以在浏览器中打开Haproxy监控界面,端口4001,在配置文件中定义有用户名admin,密码abc123456。
我这边访问的是http://192.168.63.144:4001/dbs,并且要使用用户名密码进行登录(小插曲,使用的是Basic登录,我的Chrome不知为何被屏蔽了,我最后用的火狐)

这时候我们手动挂掉一个Docker节点,看一下变化(我们会发现已经显示挂掉了)

8、Haproxy不存储数据,只转发数据。可以在数据库中建立Haproxy的连接,端口4002,用户名和密码为数据库集群的用户名和密码
为什么要采用双机热备
单节点Haproxy不具备高可用,必须要有冗余设计
双机就是两个请求处理程序,比如两个haproxy,当一个挂掉的时候,另外 一个可以顶上。热备我理解就是keepalive。在haproxy 容器中安装keepalive。

虚拟IP地址
linux系统可以在一个网卡中定义多个IP地址,把这些地址分配给多个应用程序,这些地址就是虚拟IP,Haproxy的双机热备方案最关键的技术就是虚拟IP。
关键就是虚拟ip,定义一个虚拟ip,然后比如两个haproxy分别安装keepalive镜像,因为haproxy是ubuntu系统的,所以安装用apt-get,keepalive是作用是抢占虚拟ip,抢到的就是主服务器,没有抢到的就是备用服务器,然后两个keepalive进行心跳检测(就是创建一个用户到对方那里试探,看是否还活着,mysql的集群之间也是心跳检测),如果 挂掉抢占ip。所以在启动keepalive 之前首先要编辑好他的配置文件,怎么抢占,权重是什么,虚拟ip是什么,创建的用户交什么。配置完启动完以后可以ping一下看是否正确,然后将虚拟ip映射到局域网的ip

利用Keepalived实现双机热备
- 定义虚拟IP
- 在Docker中启动两个Haproxy容器,每个容器中还需要安装Keepalived程序(以下简称KA)
- 两个KA会争抢虚拟IP,一个抢到后,另一个没抢到就会等待,抢到的作为主服务器,没抢到的作为备用服务器
- 两个KA之间会进行心跳检测,如果备用服务器没有受到主服务器的心跳响应,说明主服务器发生故障,那么备用服务器就可以争抢虚拟IP,继续工作
- 我们向虚拟IP发送数据库请求,一个Haproxy挂掉,可以有另一个接替工作

Нaproxy双机热备方案

Docker中创建两个Haproxy,并通过Keepalived抢占Docker内地虚拟IP
Docker内的虚拟IP不能被外网,所以需要借助宿主机Keepalived映射成外网可以访问地虚拟IP
安装Keepalived
1、进入Haproxy容器,安装Keepalived:
$ docker exec -it h1 bash apt-get update apt-get install keepalived
2、Keepalived配置文件(Keepalived.conf):
Keepalived的配置文件是/etc/keepalived/keepalived.conf
# vim /etc/keepalived/keepalived.conf
vrrp_instance VI_1 {
state MASTER # Keepalived的身份(MASTER主服务要抢占IP,BACKUP备服务器不会抢占IP)。
interface eth0 # docker网卡设备,虚拟IP所在
virtual_router_id 51 # 虚拟路由标识,MASTER和BACKUP的虚拟路由标识必须一致。从0~255
priority 100 # MASTER权重要高于BACKUP数字越大优先级越高
advert_int 1 # MASTER和BACKUP节点同步检查的时间间隔,单位为秒,主备之间必须一致
authentication { # 主从服务器验证方式。主备必须使用相同的密码才能正常通信
auth_type PASS
auth_pass 123456
}
virtual_ipaddress { # 虚拟IP。可以设置多个虚拟IP地址,每行一个
172.18.0.201
}
}
3、启动Keepalived
service keepalived start
启动成功后,通过ip a可以查看网卡中虚拟IP是否成功,另外可以在宿主机中ping成功虚拟IP172.18.0.201
4、可以按照以上步骤,再另外创建一个Haproxy容器,注意映射的宿主机端口不能重复,Haproxy配置一样。然后在容器中安装Keepalived,配置也基本一样(可以修改优先权重)。这样便基本实现了Haproxy双机热备方案
命令如下:
创建Haproxy容器(name=h2的原因是为了高可用)
# 这里要加 --privileged docker run -it -d -p 4003:8888 -p 4004:3306 -v /home/soft/haproxy:/usr/local/etc/haproxy --name h2 --net=net1 --ip 172.18.0.8 --privileged haproxy
进入容器
docker exec -it h2 bash
在容器bash中启动Haproxy
haproxy -f /usr/local/etc/haproxy/haproxy.cfg
接下来便可以在浏览器中打开Haproxy监控界面,端口4003,在配置文件中定义有用户名admin,密码abc123456。
我这边访问的是http://192.168.63.144:4003/dbs,并且要使用用户名密码进行登录(小插曲,使用的是Basic登录,我的Chrome不知为何被屏蔽了,我最后用的火狐)
安装Keepalived:
apt-get update apt-get install keepalived
Keepalived配置文件(Keepalived.conf):
Keepalived的配置文件是/etc/keepalived/keepalived.conf
# vim /etc/keepalived/keepalived.conf
vrrp_instance VI_1 {
state MASTER # Keepalived的身份(MASTER主服务要抢占IP,BACKUP备服务器不会抢占IP)。
interface eth0 # docker网卡设备,虚拟IP所在
virtual_router_id 51 # 虚拟路由标识,MASTER和BACKUP的虚拟路由标识必须一致。从0~255
priority 100 # MASTER权重要高于BACKUP数字越大优先级越高
advert_int 1 # MASTER和BACKUP节点同步检查的时间间隔,单位为秒,主备之间必须一致
authentication { # 主从服务器验证方式。主备必须使用相同的密码才能正常通信
auth_type PASS
auth_pass 123456
}
virtual_ipaddress { # 虚拟IP。可以设置多个虚拟IP地址,每行一个
172.18.0.201
}
}
启动Keepalived
service keepalived start
启动成功后,通过ip a可以查看网卡中虚拟IP是否成功,另外可以在宿主机中ping成功虚拟IP172.18.0.201
实现外网访问虚拟IP
查看当前局域网IP分配情况:
yum install nmap -y nmap -sP 192.168.1.0/24
在宿主机中安装Keepalived
yum install keepalived
宿主机Keepalived配置如下(/etc/keepalived/keepalived.conf):
vrrp_instance VI_1 {
state MASTER
#这里是宿主机的网卡,可以通过ip a查看当前自己电脑上用的网卡名是哪个
interface ens33
virtual_router_id 100
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
#这里是指定的一个宿主机上的虚拟ip,一定要和宿主机网卡在同一个网段,
#我的宿主机网卡ip是192.168.63.144,所以指定虚拟ip是160
192.168.63.160
}
}
#接受监听数据来源的端口,网页入口使用
virtual_server 192.168.63.160 8888 {
delay_loop 3
lb_algo rr
lb_kind NAT
persistence_timeout 50
protocol TCP
#把接受到的数据转发给docker服务的网段及端口,由于是发给docker服务,所以和docker服务数据要一致
real_server 172.18.0.201 8888 {
weight 1
}
}
#接受数据库数据端口,宿主机数据库端口是3306,所以这里也要和宿主机数据接受端口一致
virtual_server 192.168.63.160 3306 {
delay_loop 3
lb_algo rr
lb_kind NAT
persistence_timeout 50
protocol TCP
#同理转发数据库给服务的端口和ip要求和docker服务中的数据一致
real_server 172.18.0.201 3306 {
weight 1
}
}
启动Keepalived服务
service keepalived start #service keepalived status #service keepalived stop
之后其他电脑便可以通过虚拟IP192.168.63.160的8888和3306端口来访问宿主机Docker中的172.18.0.201的相应端口。
暂停PXC集群的办法
vi /etc/sysctl.conf #文件中添加net.ipv4.ip_forward=1这个配置 systemctl restart network
然后把虚拟机挂起
热备份数据
冷备份
- 冷备份是关闭数据库时候的备份方式,通常做法是拷贝数据文件
- 是简单安全的一种备份方式,不能在数据库运行时备份。
- 大型网站无法做到关闭业务备份数据,所以冷备份不是最佳选择
热备份
热备份是在系统运行状态下备份数据
MySQL常见的热备份有LVM和XtraBackup两种方案
- LVM:linux的分区备份命令,可以备份任何数据库;但是会对数据库加锁,只能读取;而且命令复杂
- XtraBackup:不需要锁表,而且免费
XtraBackup
XtraBackup是一款基于InnoDB的在线热备工具,具有开源免费,支持在线热备,占用磁盘空间小,能够非常快速地备份与恢复mysql数据库
- 备份过程中不锁表,快速可靠
- 备份过程中不会打断正在执行地事务
- 备份数据经过压缩,占用磁盘空间小
全量备份和增量备份
- 全量备份:备份全部数据。备份过程时间长,占用空间大。第一次备份要使用全量备份
- 增量备份: 只备份变化的那部分数据。备份的时间短,占用空间小。第二次以后使用增量备份
PXC全量备份
备份要在某个PXC节点的容器内进行,但应该把备份数据保存到宿主机内。所以采用目录映射技术。先新建Docker卷:
docker volume create backup
挑选一个PXC节点node1,将其容器停止并删除,然后重新创建一个增加了backup目录映射的node1容器
docker stop node1 docker rm node1 # 数据库数据保存在Docker卷v1中,不会丢失 # 参数改变: # 1. -e CLUSTER_JOIN=node2;原来其他节点是通过node1加入集群的,现在node1重新创建,需要选择一个其他节点加入集群 # 2. -v backup:/data;将Docker卷backup映射到容器的/data目录 docker run -d -u root -p 3306:3306 -e MYSQL_ROOT_PASSWORD=abc123456 -e CLUSTER_NAME=PXC -e XTRABACKUP_PASSWORD=abc123456 -e CLUSTER_JOIN=node2 -v v1:/var/lib/mysql -v backup:/data --network=net1 --ip 172.18.0.2 --name=node1 pxc
在node1容器中安装percona-xtrabackup-24
docker exec -it node1 bash apt-get update apt-get install percona-xtrabackup-24
之后便可以执行如下命令进行全量备份,备份后的数据会保存在/data/backup/full目录下:
mkdir /data/backup mkdir /data/backup/full #不建议,已过时 innobackupex --backup -u root -p abc123456 --target-dir=/data/backup/full xtrabackup --backup -uroot -pabc123456 --target-dir=/data/backup/full
官方文档已经不推荐使用innobackupex,而推荐使用xtrabackup命令
PXC全量还原
数据库可以热备份,但是不能热还原,否则会造成业务数据和还原数据的冲突。
对于PXC集群为了避免还原过程中各节点数据同步冲突的问题,我们要先解散原来的集群,删除节点。然后新建节点空白数据库,执行还原,最后再建立起其他集群节点。
还原前还要将热备份保存的未提交的事务回滚,还原之后重启MySQL
停止并删除PXC集群所有节点
docker stop node1 node2 node3 node4 node5 docker rm node1 node2 node3 node4 node5 docker volume rm v1 v2 v3 v4 v5
按照之前的步骤重新创建node1容器,并进入容器,执行冷还原
# 创建卷 docker volume create v1 # 创建容器 docker run -d -p 3306:3306 -e MYSQL_ROOT_PASSWORD=abc123456 -e CLUSTER_NAME=PXC -e XTRABACKUP_PASSWORD=abc123456 -v v1:/var/lib/mysql -v backup:/data --name=node1 --network=net1 --ip 172.18.0.2 pxc # 以root身份进入容器 docker exec -it -uroot node1 bash # 删除数据 rm -rf /var/lib/mysql/* # 准备阶段 xtrabackup --prepare --target-dir=/data/backup/full/ # 执行冷还原 xtrabackup --copy-back --target-dir=/data/backup/full/ # 更改还原后的数据库文件属主 chown -R mysql:mysql /var/lib/mysql # 退出容器后,重启容器 docker stop node1 docker start node1
下一篇:Linux调整命令历史方法详解